Welcome to CherieLi's Blog!
世上无知己,唯花解我心-
可变参数模板
variadic templates
1.可变参数函数实现原理
指定参数的函数实现,通过指定的参数名访问
不指定参数的函数实现,函数调用的参数进行压栈处理(从右到左进行压栈)
可变参数函数:参数个数可变、参数类型不定的函数
“…” 表示0个或多个类型未知的参数
最常见的例子:
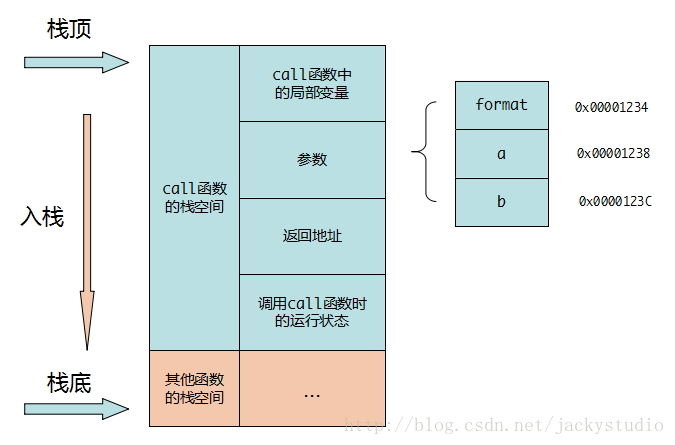
int printf(const char * format, ...)调用:
int a=5; char b='b'; printf("%d and %c",a,b);参数压栈顺序:b,a,format
函数调用内存结构:
2.声明和定义
对不定参数部分用”…“表示
可变参数至少包含一个参数,用来寻址,实现对所有参数的访问
已知的指定参数必须声明在函数最左端
错误的声明:
void func(...)或者
void func(..., int a);3.示例
求和。第一个参数指定要计算的值的个数
格式化字符串。第一个参数指定占位符
#include <iostream> #include <cstdarg> #include <cstdio> #include <vector> using namespace std; int sum(int num,...) //利用变长函数进行求和运算 { int sumval=0; va_list args; //定义一个可变参数列表 va_start(args,num); //初始化args指向强制参数arg的下一个参数 while(num--) { sumval+=va_arg(args,int); //获取参数的值 } va_end(args); //释放args return sumval; } string format(const char* format, ...) //格式化字符串 { string var_str; va_list ap; va_start(ap, format); int len = _vscprintf(format, ap); if (len > 0) { vector<char> buf(len + 1); vsprintf(&buf.front(), format, ap); var_str.assign(buf.begin(), buf.end() - 1); } va_end(ap); return var_str; } int main() { cout<<sum(5,10,23,78,65,9)<<endl; cout<<sum(8,1,2,3,4,5,6,7,8)<<endl; cout<<format("%s#%s#%s","this","is","me"); //cout<<sum(5,10.23,23.78,78.59,65.12,9.08)<<endl; return 0; }参数类型不匹配,程序会出错,可能导致程序崩溃。
4.可变参数模板
“…” 表示0个或多个类型未知的参数,于是可以帮助我们完成递归
#include <iostream> #include <bitset> using namespace std; void print() { } template <typename T,typename... Types> //...用于模板参数 void print(const T& firstArg, const Types&... args)//...用于函数参数类型 { cout<<firstArg<<endl; print(args...);//...用于函数参数 } int main() { print(7.5, "hello", bitset<16>(377),42); return 0; }运行结果:

template<typename... Types> void print(const Types&... args) { }5.调用关系
案例1:
class CustomerHash{ public: std::size_t operator()(const Customer& c) const{ return hash_val(c.fname,c.lname,c.no); } }; template<typename...Types> inline size_t hash_val(const Types&... args) //函数1 { size_t seed=0; hash_val(seed,args...); return seed; } template<typename T, typename... Types> inline void hash_val(size_t& seed, const T& val, const Types&... args) //函数2 { hash_combine(seed,val); hash_val(seed,args...); } template <typename T> inline void hash_val(size_t& seed, const T& val) //函数3 { hash_combine(seed,val); } template <typename T> inline void hash_combine(size_t& seed, const T&val) //函数4 { seed^=std::hash<T>()(val)+0x9e3779b9+(seed<<6)+(seed>>2); }案例2:
template<typename... Values> class tuple; template<>class tuple<>{}; template<typename Head,typename... Tail> class tuple<Head,Tail...>:private tuple<Tail...> { typedef tuple<Tail...> inherited; public: tuple(){} tuple(Head v,Tail... vtail):m_head(v),inherited(vtail...){} typename Head::type head(){return m_head;} inherited& tail(){return *this;} protected: Head m_head; }; tuple<int,float,string> t(41,6.3,"nico"); t.head() //41 t.tail() //6.3, nico t.tail().head() //6.3 &(t.tail) //nico6.小结
…就是一个所谓的包(pack)
用于template parameters,就是template parameters pack (模板参数包)
用于function parameter types,就是function parameter types pack(函数参数类型包)
用于function parameters,就是function parameters pack(函数参数包)
-
rpc 学习
什么是RPC
Remote Procedure Call Protocol,远程过程调用
入参、执行运算逻辑、出参。三个动作都发生在同一个进程空间里是本地函数调用。
两个进程约定一个协议格式,入参、执行运算逻辑、出参。就是远程调用。
RPC框架的职责是
· client端:序列化、反序列化、连接池管理、负载均衡、故障转移、队列管理,超时管理、异步管理等等
· server端:服务端组件、服务端收发包队列、io线程、工作线程、序列化反序列化等
序列化(Serialization),就是将“对象”形态的数据转化为“连续空间二进制字节流”形态数据的过程。这个过程的逆过程叫做反序列化。
怎么进行序列化?
使用成熟协议xml/json
自定义二进制协议来序列化对象
rpc和http的区别
HTTP 指的是通信协议。 RPC 则是远程调用,其对应的是本地调用。RPC 的通信可以用 HTTP 协议,也可以自定义协议,是不做约束的。 RPC主要用于公司内部服务调用,性能消耗低,传输效率高,服务治理方便。HTTP主要用于对外的异构环境,浏览器调用,APP接口调用,第三方接口调用等等。
参考文档
https://blog.csdn.net/xuduorui/article/details/78278808
https://developer.aliyun.com/article/713311
离不开的微服务架构,脱不开的RPC细节https://bbs.huaweicloud.com/blogs/337073
千字带你了解什么是 RPC 协议gRPC
-
锁优化
互斥锁与自旋锁
互斥锁 是阻塞锁,当某线程无法获取互斥锁时,该线程会被直接挂起,该线程不再消耗CPU时间,当其他线程释放互斥锁后,操作系统会激活那个被挂起的线程,让其投入运行。
自旋锁 是一种非阻塞锁,如果某线程需要获取自旋锁,但该锁已经被其他线程占用时,该线程不会被挂起,而是在不断的消耗CPU的时间,不停的试图获取自旋锁。
std::mutex临界区较小,可考虑使用更轻量级的锁,例如spin lock; 使用tbb::spin_mutex代替std::mutex
std::mutex用于保护std::unordered_map,可考虑使用lock free map替代原本的std::unordered_map。
spinlock/mutex
轻量级互斥锁,用户不可见,适用于多线程间简单共享数据结构的修改保护,只有exclusive(独占)模式。一般基于CAS类的原子操作实现,当ptr的值为0时swap为1,加锁成功,如果ptr的值为1,则swap失败,加锁不成功,继续等待重试。两种锁适用于不同场景:
1.如果是多核处理器,如果预计线程等待锁的时间很短,使用自旋锁是划算的。
2.如果是多核处理器,如果预计线程等待锁的时间较长,建议使用互斥锁。
3.如果是单核处理器,一般建议不要使用自旋锁。因为,在同一时间只有一个线程是处在运行状态,那如果运行线程发现无法获取锁,只能等待解锁,但因为自身不挂起,所以那个获取到锁的线程没有办法进入运行状态,只能等待运行线程把操作系统分给它的时间片用完,才能有机会被调度。这种情况下使用自旋锁的代价很高。
4.如果加锁的代码经常被调用,但竞争情况很少发生时,应该优先考虑使用自旋锁,自旋锁的开销比较小,互斥锁的开销较大。
共享锁(读锁)
共享锁是指该锁可被多个线程所持有。悲观锁
悲观锁认为对于同一个数据的并发操作,一定是会发生修改的,哪怕没有修改,也会认为修改。因此对于同一个数据的并发操作,悲观锁采取加锁的形式。悲观的认为,不加锁的并发操作一定会出问题。乐观锁
乐观锁则认为对于同一个数据的并发操作,是不会发生修改的。在更新数据的时候,会采用尝试更新,不断重新的方式更新数据。乐观的认为,不加锁的并发操作是没有事情的。公平锁
公平锁是指多个线程按照申请锁的顺序来获取锁(使用队列进行排序,FIFO)非公平锁
非公平锁是指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取锁。(概率上会造成优先级反转或者饥饿现象)阻塞锁
阻塞锁改变了线程的运行状态,让线程进入阻塞状态进行等待,当获得相应的信号(唤醒,时间)时,才可以进入线程的准备就绪状态,准备就绪状态的所有线程,通过竞争,进入运行状态。阻塞锁的优势在于,阻塞的线程不会占用cpu时间,不会导致cpu占用率过高,但进入时间以及恢复时间都要比自旋锁略慢。 在竞争激烈的情况下,阻塞锁的性能要明显高于自旋锁。 理想的情况:在线程竞争不激烈下使用自旋锁,竞争激烈下使用阻塞锁。无锁队列
https://www.cnblogs.com/catch/p/5129586.htmlCAS操作
type __sync_val_compare_and_swap(type *ptr, type oldval type newval, …)
比较ptr与oldval的值,如果两者相等,则将newval更新到ptr并返回操作之前*ptr的值。
http://wfeii.com/2021/08/07/atomic.htmlFADD操作
type __sync_fetch_and_add (type *ptr, type value); 函数提供原子加并返回原来ptr的值。Latch/RWLock
轻量级读写锁,用户不可见,其加锁的范围相对于spinlock来说范围更进一步扩大,适用于临界区较大且具有复杂的逻辑处理流程,更适合读多写少的场景)。加锁对象通常类似Btree index等结构体。锁模式分为shared(共享)和exclusive(独占)两种模式。Innodb transaction lock
https://zhuanlan.zhihu.com/p/493415374MySQL MDL lock
https://zhuanlan.zhihu.com/p/130318750锁性能优化
1.无锁编程:在多线程竞争激烈的情况下,使用无锁算法的整体吞吐量会优于加锁的算法,因为它避免了调度延时和频繁的上下文切换。如:单生产者单消费者的无锁队列。
2.大锁变小锁:并发任务高的场景下,如果系统中存在唯一的全局变量,那么每个CPU core都会申请这个全局变量对应的锁,导致这个锁的争抢严重。可以基于业务逻辑,为每个CPU core或者线程分配对应的资源。
3.使用gcc自带的原子操作:推荐使用GCC(7.3.0)实现的atomic系列代码,跨平台移植性好,性能也非常好。
4.使用自带内存屏障的指令:推荐使用ldaxr/stlxr指令实现锁或原子操作,替换ldxr/stxr +内存屏障(dmb)的实现。
5.调整线程数达到最佳并发效果:多线程可以提升系统吞吐量,但是却会增加锁的争抢,更会增加线程切换带来的CPU损耗。
6.避免cache line伪共享:通过数据结构优化或字节对齐,将频繁读和频繁写的数据放入不同Cache line,减少“锁”数据结构的伪共享。spinlock
spinlock是个while循环,会导致cpu使用率变高,一般仅用在短暂访问临界区场景。
-
gdb调试方法
- 什么是GDB
- Linux下core文件gdb调试方法
- GDB 常用操作
- 1. 显示版本信息
- 2. 显示gdb版权相关信息
- 3. 启动时不显示提示信息
- 4. gdb退出时不显示提示信息
- 5. 输出信息多时不会暂停输出
- 6. 列出函数的名字
- 7. 是否进入带调试信息的函数
- 8. 进入不带调试信息的函数
- 9. 退出正在调试的函数
- 10. 直接执行函数
- 11. 打印函数堆栈帧信息
- 12. 打印尾调用堆栈帧信息
- 13. 选择函数堆栈帧
- 14. 向上或向下切换函数堆栈帧
- 15. 在匿名空间设置断点
- 16. 在程序地址上打断点
- 17. 在程序入口处打断点
- 18. 在文件行号上打断点
- 19. 保存已经设置的断点
- 20. 设置临时断点
- 21. 设置条件断点
- 22. 忽略断点
- 23. 设置观察点
- 从同事那里学来的gdb调试小技巧
- gdb调试进阶
- gdb图形化界面
- gdb配置文件调试方法
- gstack (卡住问题定位)
- pstack
- 参考链接:
什么是GDB
Gdb是GNU开源组织发布的一个强大的UNIX下的程序调试工具
Gdb可以通过ptrace来控制指定的进程
strip -d
strip –s
如何提取符号表使用,编译时增加-g选项
如何使用gdb调试一个程序
使用gdb有三种常用方式:
\1. gdb [program] 使用gdb启动一个程序并调试
\2. gdb [program]+[core] 使用gdb调试core文件
\3. gdb [program]+[pid] 使用gdb调试已在运行的程序(通过pid)
linux上进程的几种状态:
R(TASK_RUNNING),可执行状态&运行状态(在run_queue队列里的状态)
S(TASK_INTERRUPTIBLE),可中断的睡眠状态,可处理signal
D(TASK_UNINTERRUPTIBLE),不可中断的睡眠状态,可处理signal,有延迟
Z(TASK_DEAD-EXIT_ZOMBIE)退出状态,进程称为僵尸进程,不可被kill,即不相应任务信号,无法用SIGKILL杀死
T(TASK_STOPPED or TASK_TRACED),暂停状态或跟踪状态,不可处理signal,因为根本没有时间片运行代码
X(TASK_DEAD-EXIT_DEAD),退出状态,进程即将被销毁
数据断点
数据断点在gdb中分为硬件断点和软件断点
Gdb中调用数据断点的指令分为watch,rwatch,awatch
watch:写型数据断点,当指定内存被修改时触发
rwatch:读型数据断点,当指定内存被访问时触发
awatch:综合上述两种
指令介绍
\1. help
help是一个查询指令,可以使用help来查看其他指令的用法,例如help print,就可以看到print的介绍以及用法
\2. shell
启动标准shell执行command string
\3. print
用于打印的一个指令
p /x 打印16进制
p/d 打印有符号整型数
u 打印无符号整型数
p/o 打印8进制
p/t 打印二进制
p/a 作为一个地址(系统会查找处于哪个函数)
p/c 作为要给ASCII字符
p/f 浮点数
p/s 字符串
\4. set
用于设置gdb内部的一些环境与运行时的参数
\5. show
show描述gdb本身的状态
show version
\6. info
描述程序的状态
info args显示传递给函数的参数
info registers 列出寄存器数据
info breakpoints 列出设置的断点
info thread 查看线程状态
\7. -cd/directory
指定源码路径(当当前执行gdb的位置不在源码目录下或二进制不在源码目录下时,否则会自动查找)
\8. file
用于加载调试用的二进制文件,不过一般都在启动gdb时直接加载
\9. backtrace
可以查看调用栈,在调试core时一般首先就是使用bt查看调用栈信息
\10. list
用于列出源代码
list+:只打印最近打印行后的代码
\11. thread
切换线程,适用于多线程调试时使用
\12. x
以多种格式直接查看内存,与程序数据类型无关
x/nfu
n:10进制数,指定显示多长的内存,默认为1
f:多了i格式(机器指令格式),其他格式同print, 模式时x型,即16进制
u:单元大小,b 表示1字节,h表示2字节,w表示4字节(默认),g表示8字节
\13. break
设置断点
\14. commands
用于在break后增加一些指令,增加break的可操作性
\15. define
将一些gdb的指令组合起来,方便连续的重复使用
\16. (gdb)info shared library
\17. (gdb) add-symbol-file
\18. (gdb)show follow-forkk-mode
\19. (gdb) info inferiors
Linux下core文件gdb调试方法
在程序不寻常退出时,内核会在当前工作目录下生成一个core文件(是一个内存映像,同时加上调试信息)。
使用gdb来查看core文件,可以指示出导致程序出错的代码所在文件和行数。
exit
exit会附带清理工作,比如全局对象、静态对象的析构,别的线程还在跑,很容易发生一些难以预测的结果。(代码中尽量不要用)
exit的清理工作还没做完,进程不会退出,别的线程还在跑,一访问被析构掉的静态对象就core了。1.core文件的生成开关和大小限制
1)使用ulimit -c命令可查看core文件的生成开关。若结果为0,则表示关闭了此功能,不会生成core文件。 2)使用ulimit -c filesize命令,可以限制core文件的大小(filesize的单位为kbyte)。若ulimit -c unlimited,则表示core文件的大小不受限制。如果生成的信息超过此大小,将会被裁剪,最终生成一个不完整的core文件。在调试此core文件的时候,gdb会提示错误。 3)使用ulimit -a命令可以查看显示所有的用户定制,其中选项 -a 代表“ all ”
2.core文件的名称和生成路径
core文件生成路径: 输入可执行文件运行命令的同一路径下。 若系统生成的core文件不带其它任何扩展名称,则全部命名为core。新的core文件生成将覆盖原来的core文件。 1)/proc/sys/kernel/core_uses_pid可以控制core文件的文件名中是否添加pid作为扩展。文件内容为1,表示添加pid作为扩展名,生成的core文件格式为core.xxxx;为0则表示生成的core文件同一命名为core。
查看文件对应的值:
cat /proc/sys/kernel/core_uses_pid 可通过以下命令修改此文件: echo “1” > /proc/sys/kernel/core_uses_pid 2)/proc/sys/kernel/core_pattern可以控制core文件保存位置和文件名格式。
查看文件对应的保存位置
cat /proc/sys/kernel/core_pattern 可通过以下命令修改此文件: echo “/corefile/core-%e-%p-%t” > core_pattern,可以将core文件统一生成到/corefile目录下,产生的文件名为core-命令名-pid-时间戳 以下是参数列表: %p - insert pid into filename 添加pid %u - insert current uid into filename 添加当前uid %g - insert current gid into filename 添加当前gid %s - insert signal that caused the coredump into the filename 添加导致产生core的信号 %t - insert UNIX time that the coredump occurred into filename 添加core文件生成时的unix时间 %h - insert hostname where the coredump happened into filename 添加主机名 %e - insert coredumping executable name into filename 添加命令名
3.core文件的查看
core文件需要使用gdb来查看。 gdb ./a.out core-file core.xxxx 使用bt命令即可看到程序出错的地方。 以下两种命令方式具有相同的效果,但是在有些环境下不生效,所以推荐使用上面的命令。 1)gdb -core=core.xxxx file ./a.out bt 2)gdb -c core.xxxx file ./a.out bt
4.开发板上使用core文件调试
如果开发板的操作系统也是linux,core调试方法依然适用。如果开发板上不支持gdb,可将开发板的环境(依赖库)、可执行文件和core文件拷贝到PC的linux下。 在PC上调试开发板上产生的core文件,需要使用交叉编译器自带的gdb,并且需要在gdb中指定solib-absolute-prefix和solib-search-path两个变量以保证gdb能够找到可执行程序的依赖库路径。有一种建立配置文件的方法,不需要每次启动gdb都配置以上变量,即:在待运行gdb的路径下建立.gdbinit。 配置文件内容: set solib-absolute-prefix YOUR_CROSS_COMPILE_PATH set solib-search-path YOUR_CROSS_COMPILE_PATH set solib-search-path YOUR_DEVELOPER_TOOLS_LIB_PATH handle SIG32 nostop noprint pass 注意:待调试的可执行文件,在编译的时候需要加-g,core文件才能正常显示出错信息!有时候core信息很大,超出了开发板的空间限制,生成的core信息会残缺不全而无法使用,可以通过挂载到PC的方式来规避这一点。
5.一个能产生core文件的小型案例
#include <stdio.h>; #include <stdlib.h>; int crash() { char *xxx = "crash!!"; xxx[1] = 'D'; // 写只读存储区! return 2; } int foo() { return crash(); } int main() { return foo(); }gcc -g a.cpp -o a
./a
Segmentation fault (core dumped)
如何查看进程挂在哪里了?如何定位到行?
gdb a /home/corefile/core-1002-a-20327-1565785192
Core was generated by `./a’. Program terminated with signal 11, Segmentation fault. #0 0x00000000004004e1 in crash () at a.c:7 7 xxx[1] = ‘D’; // 写只读存储区!
GDB 常用操作
上边的程序比较简单,不需要另外的操作就能直接找到问题所在。现实却不是这样的,常常需要进行单步跟踪,设置断点之类的操作才能顺利定位问题。下边列出了GDB一些常用的操作。
- 启动程序:run
-
设置断点:b 行号 函数名 - 删除断点:delete 断点编号
- 禁用断点:disable 断点编号
- 启用断点:enable 断点编号
- 单步跟踪:next 也可以简写 n
- 单步跟踪:step 也可以简写 s
- 打印变量:print 变量名字
- 设置变量:set var=value
- 查看变量类型:ptype var
- 顺序执行到结束:cont
- 顺序执行到某一行: util lineno
- 打印堆栈信息:bt
1. 显示版本信息
使用gdb时,如果想查看gdb版本信息,可以使用“
show version”命令:GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-114.el7
Copyright (C) 2013 Free Software Foundation, Inc.
2. 显示gdb版权相关信息
使用gdb时,如果想查看gdb版权相关信息,可以使用“
show copying”命令或者“
show warranty”命令3. 启动时不显示提示信息
gdb在启动时会显示提示信息。如果不想显示这个信息,则可以使用-q选项把提示信息关掉
$ gdb -q
4. gdb退出时不显示提示信息
可以在gdb中使用如下命令把提示信息关掉:
(gdb) set confirm off5. 输出信息多时不会暂停输出
使用“
set pagination off”或者“set height 0”命令。这样gdb就会全部输出,中间不会暂停。6. 列出函数的名字
使用“
info functions”命令可以列出可执行文件的所有函数名称(gdb) info functions thre*可以看到gdb只会列出名字里包含“
thre”的函数。7. 是否进入带调试信息的函数
使用gdb调试遇到函数时,使用step命令(缩写为s)可以进入函数(函数必须有调试信息)。
可以使用next命令(缩写为n)不进入函数,gdb会等函数执行完,再显示下一行要执行的程序代码。
8. 进入不带调试信息的函数
printf函数不带调试信息,所以“s”命令(s是“step”缩写)无法进入printf函数。
可以执行“set step-mode on”命令,这样gdb就不会跳过没有调试信息的函数
9. 退出正在调试的函数
当单步调试一个函数时,如果不想继续跟踪下去了,可以有两种方式退出。
第一种用“finish”命令,这样函数会继续执行完,并且打印返回值,然后等待输入接下来的命令。
第二种用“return”命令,这样函数不会继续执行下面的语句,而是直接返回。
10. 直接执行函数
使用gdb调试程序时,可以使用“
call”或“print”命令直接调用函数执行。(gdb) start (gdb) call func() (gdb) print func()11. 打印函数堆栈帧信息
可以使用“
i frame”命令(i是info命令缩写)显示函数堆栈帧信息。(gdb) i frame (gdb) i registers (gdb) disassemble func执行“
i frame”命令后,输出了当前函数堆栈帧的地址,指令寄存器的值,局部变量地址及值等信息,可以对照当前寄存器的值和函数的汇编指令看一下。12. 打印尾调用堆栈帧信息
查看
main函数汇编代码:(gdb) disassemble main在函数
a入口处打上断点,程序停止后,打印堆栈帧信息(gdb) i frame设置“
debug entry-values”选项为非0的值,这样除了输出正常的函数堆栈帧信息以外,还可以输出尾调用的相关信息(gdb) set debug entry-values 1 (gdb) b test.c:4 (gdb) r (gdb) i frame可以看到输出了“
tailcall: initial:”信息13. 选择函数堆栈帧
当程序暂停后,可以用“
frame n”命令选择函数堆栈帧,其中n是层数。(gdb) b test.c:5 (gdb) r (gdb) bt (gdb) frame 2 (gdb) i frame (gdb) frame 0x7fffffffe568使用“
i frame”命令可以知道0x7fffffffe568是func2的函数堆栈帧地址,使用“frame 0x7fffffffe568”可以切换到func2的函数堆栈帧。14. 向上或向下切换函数堆栈帧
用gdb调试程序时,当程序暂停后,可以用“
up n”或“down n”命令向上或向下选择函数堆栈帧,其中n是层数。(gdb) b test.c:5
(gdb) r
(gdb) bt
(gdb) frame 2
(gdb) up 1
(gdb) down 2
先执行“
frame 2”命令,切换到fun3函数。执行“
up 1”命令,此时会切换到main函数,也就是会往外层的堆栈帧移动一层。执行“
down 2”命令后,又会向内层堆栈帧移动二层。如果不指定n,则n默认为1.“
up-silently n”和“down-silently n”这两个命令,与“up n”和“down n”命令区别在于,切换堆栈帧后,不会打印信息15. 在匿名空间设置断点
如果要对namespace Foo中的foo函数设置断点``
(gdb) b Foo::foo如果要对匿名空间中的bar函数设置断点
(gdb) b (anonymous namespace)::bar16. 在程序地址上打断点
当调试汇编程序,或者没有调试信息的程序时,经常需要在程序地址上打断点,方法为
b *address(gdb) b *0x40052217. 在程序入口处打断点
获取程序入口: 方法一: $ strip a.out $ readelf -h a.out得到:``Entry point address: 0x400440方法二:``$ gdb a.out >>> info files得到:``Entry point address: 0x400440 (gdb) b *0x400440 (gdb) r18. 在文件行号上打断点
如果要在当前文件中的某一行打断点,直接
b linenum即可(gdb) b 7显式指定文件,
b file:linenum(gdb) b file.c:6 (gdb) i breakpoints (gdb) b a/file.c:619. 保存已经设置的断点
(gdb) save breakpoints file-name-to-save (gdb) source file-name-to-save (gdb) info breakpoints20. 设置临时断点
如果想让断点只生效一次,可以使用“tbreak”命令(缩写为:tb)
(gdb) tb a.c:15 (gdb) i b (gdb) r (gdb) i b21. 设置条件断点
只有在条件满足时,断点才会被触发,命令是“
break … if cond”(gdb) start (gdb) b 10 if i==101 (gdb) r (gdb) p sum22. 忽略断点
在设置断点以后,可以忽略断点,命令是“
ignore bnum count”:意思是接下来count次编号为bnum的断点触发都不会让程序中断,只有第count + 1次断点触发才会让程序中断。(gdb) b 10 (gdb) ignore 1 5 (gdb) r (gdb) p i $1 = 623. 设置观察点
使用“
watch”命令设置观察点,也就是当一个变量值发生变化时,程序会停下来。(gdb) start (gdb) watch a (gdb) r (gdb) c也可以使用“
watch *(data type*)address”这样的命令(gdb) p &a (gdb) watch *(int*)0x6009c8 (gdb) r (gdb) c从同事那里学来的gdb调试小技巧
1) set scheduler-locking on // 关闭线程调度器, 只有当前线程会活动,其他线程被阻塞
2) set logging on //打开屏幕输出到本地文件,当前文件夹下生成gdb.txt 记录所有gdb调试结果
3) b 文件名:行号 if 判断条件 // 条件断点
4) shell ls -l // gdb界面执行shell 命令
6) set pagination off // 关闭分页打印,设置不分页
gdb调试进阶
\1. 我们可以通过GDB attach 的方式来调试一个正在运行的线程:
- A. 是
- B. 否
\2. GDB下可以通过handle SIG35 nostop noprint 来屏蔽对35号信号的接管:
- A. 是
- B. 否
\3. 下面哪个命令可以查看调用栈:
- A. b
- B. bt
- C. step
- D. next
\4. 想要查看当前寄存器信息命令:
- A. info thread
- B. info local
- C. info r
- D. bt
\5. 我们想打印addr地址开始的汇编指令:
- A. x/20wx addr
- B. p/x addr
- C. x/20i addr
- D. p addr
课后小测
\1. 想要编译有调试信息的二进制文件,需要加-g选项:
- A. 是
- B. 否
\2. GDB下可以通过thread thread_num的方式来切换当前的任务现场:
- A. 是
- B. 否
\3. 想要看函数反汇编使用下面那个命令:
- A, readelf
- B, nm
- C, ar
- D, objdump
\4. 查看test.obj带有文件名和行号的反汇编命令是:
- A, objdump -dr test.obj
- B, objdump -d -S -l test.obj
- C, readelf -s test.obj
- D, objdump -Dr test.obj
\5. 查看test.obj带有重定位信息的反汇编命令是:
- A, objdump -dr test.obj
- B, objdump -d -S -l test.obj
- C, readelf -s test.obj
- D, objdump -D test.obj
课后小测
\1. mprotect 可以单独保护4字节内存:
- A. 是
- B. 否
\2. mprotect 将内存保护后,在释放内存前是否需要去保护:
- A. 是
- B. 否
\3. GDB watch 哪个是内存被读或写时停止
- A, rwatch
- B, watch
- C, awatch
\4. mprotect 设置内存可写可读但不能执行,flag应该传多少
- A, 1
- B, 2
- C, 3
- D, 7
\5. mprotect内存只读后内存如果被写,会产生哪个信号
- A, SIGILL
- B, SIG35
- C, SIGSEGV
- D, SIGTERM
\1. arm32 环境,R13保存sp指针:
- A. 是
- B. 否
\2. arm64 环境,X30保存sp指针:
- A. 是
- B. 否
\3. x8632和x8664 cpu 传参寄存器有几个:
- A, 4, 6
- B, 4, 4
- C, 6,4
- D, 6,6
\4. arm32和arm64 cpu 传参寄存器有几个:
- A, 4, 4
- B, 4, 8
- C, 8,4
- D, 8,8
\5. 任务栈中除mips32, 一般不会存在以下哪个信息:
- A, 函数入参信息
- B, 函数指令
- C, 函数调用关系
- D, 局部变量信息
综合测试
一、单选题
\1. 假设有全部变量g_uvAddr, 如何以16进制查看该变量值:
- A. p/x g_uvAddr
- B. p/s g_uvAddr
- C. p/d g_uvAddr
- d. p/c g_uvAddr
\2. 只给线程2的funcA打断点,以下操作哪个是对的:
- A. b funcA
- B. b funcA thread 2
- C. thread apply 2 b funcA
- D. thread apply all b funcA
\3. 若当前使用内存页大小为4K,addr=0x80010110, len=0x3000, mprotect中地址和长度填写分别是多少:
- A. 0x80010110,0x3000
- B. 0x80010000,0x2000
- C. 0x80011000,0x2000
- D. 0x80010000,0x3000
\4. arm64 入参寄存器是以下哪个:
- A. EDI,ESI,EDX,ECX
- B. R0~R3
- C. X0~X7
- D. RDI,RSI,RDX,RCX,R8,R9
\5. 当前我们的调试版本为release版本,定位时需要获取汇编函数对应的文件名和行号,我们需要增加哪个编译选项后重新编译函数obj:
- A. -g 正确
- B. -o2
- C. -fPIC
- D. -Wall
二、多选题
\6. 下面的命令哪些属于GDB的调试方法:
- A. gdb ./test.out
- B. gdb -c corefile test.out
- C. gdb attach 1117
\7. GDB watch断点的方式有哪几类:
- A. watch
- B. rwatch
- C. awatch
- D. xwatch
\8. 从任务栈中我们一般可以获取哪些信息:
- A. 局部变量
- B. 函数调用关系
- C. 函数入参
D. 函数反汇编
\9. 下面哪几个命令可以查看进程号为1234的线程2(线程ID为1235)的调用栈:
- A. gdb –batch -ex “thread 2” -ex “bt” -batch -p 1234
- B. thread apply all bt
- C. thread apply 2 bt
- D. gdb –batch -ex “bt” -batch -p 1235
\10. 定位一个异常问题,我们一般需要获取哪些信息:
- A. 调用栈
- B. 寄存器信息
- C. 函数反汇编
- D. 任务栈内存
gdb图形化界面
gdb的TUI(Text User Interface) 模式还是很不错的 要注意的一点是,最好以下面的方式进入tui模式,
gdb -tui a.out 而不要打开gdb后,再通过Ctrl-x a切换到tui模式。否则在tui模式中可能不能正常使用类似Ctrl-x a 等的快捷键;按下Ctrl-x a可能只能在gdb的命令行显示^xa。
(gdb)focus 可以进入tui模式 (gdb)refresh 可以进行刷新 (gdb) layout asm 可以切换到汇编代码窗口 (gdb) winheight src + 5 代码窗口的高度扩大5行代码 (gdb) focus next/prev 调整焦点位置 (gdb) focus cmd 把焦点移到 cmd 窗口 (gdb) winheight cmd + 10https://rockhong.github.io/gdb-tui-mode.html
https://blog.csdn.net/baidu_41388533/article/details/109468392(gdb) t a a bt 查看所有线程号 (gdb) set sysroot [path] (gdb) set solib-search-path [path] (gdb) file [filename] (gdb) core [corename]gdb配置文件调试方法
gdb ./build/vdb_test ./osd.cfg
gdb不可以这么传参的
正确方法:
gdb vdb_test 进入后set args ./osd.cfg或者:
gdb --args ./build/vdb_test ./osd.cfggstack (卡住问题定位)
gstack <pid> 运行中查看进程状态pstack
pstack <pid> 运行中查看进程状态参考链接:
-
blog.csdn.net/shaovey/article/details/2744487
Linux下core文件调试方法
-
andyniu.iteye.com/blog/1965571
linux下生成core dump文件调试方法及设置
-
https://blog.csdn.net/madpointer/article/details/8856677
gdb实践(1): 进程CPU 100%排查
4.http://3ms.huawei.com/hi/group/3288655/wiki_5378755.html
mysqld 主备启动 gdb 调试
- https://www.cnblogs.com/huchong/p/10065246.html
linux每日命令(34):ps命令和pstree命令
ps –ef grep “进程名” gdb attach 4891
在完成调试之后,不要忘记用detach命令断开连接,让被调试的进程可以继续正常运行。
pstree –p 4891
以树状图显示进程PID为的进程以及子孙进程,如果有-p参数则同时显示每个进程的PID
-
https://www.ibm.com/developerworks/cn/linux/l-cn-gdbmp/index.html
使用 GDB 调试多进程程序
7.https://wizardforcel.gitbooks.io/100-gdb-tips/part1.html
100个gdb小技巧
-
gdb参考手册
https://www.eecs.umich.edu/courses/eecs373/readings/Debugger.pdf
-
gdb 调试多线程 https://blog.csdn.net/zhangye3017/article/details/80382496
-
gdb tui及cgdb的使用 https://blog.csdn.net/baidu_41388533/article/details/109468392
https://blog.csdn.net/niyaozuozuihao/article/details/91802994
-
在gem5上配置和运行PARSEC 2.1数据集
本篇介绍如何在GEM5模拟器中配置和运行PARSEC Benchmark (以ARPHA架构方式为例)。PARSEC Benchmark需要在GEM5中的全系统(full system)模式下运行,相关教程可参考:http://www.m5sim.org/PARSEC_benchmarks .